Want to auto shutdown Windows at a specific time? Here’s how to schedule a shutdown in Windows using the built-in shutdown timer.
Windows provides multiple ways to shut down the system. For instance, you can right-click the Start menu and choose “Shut down or sign out > Shut down.” For most users, the default shutdown option is good enough. However, what if you want to auto shut down Windows on schedule, i.e., schedule a shutdown?
Given the deep options in Windows OS, you’d think there is a built-in option. However, no matter how much you search within the Windows settings, you will not find any option to schedule a shutdown. That doesn’t mean you cannot do it. You have to dig deeper or be a bit creative.
There are two methods to auto shutdown Windows on schedule. The first method is helpful to set a temporary and single-use shutdown timer. The second method is useful to auto shutdown Windows at a specific time regularly, like when you go to sleep.
I will show both methods; use the one depending on your use case. Without further ado, here is how to schedule a shutdown in Windows.
Table of contents:
The steps below work the same in Windows 10 and 11.
Command to schedule shutdown in Windows
Though Windows has no visible option, you can schedule and auto shutdown Windows with a single PowerShell or Command Prompt command.
This method is helpful when you have to set a shutdown timer to auto shutdown Windows spontaneously. For instance, you can use this tip to limit how long your children can use the system.
Here’s the command to schedule a shutdown in Windows.
- Right-click the Start menu icon.
- Choose “Windows Terminal.”
- Use the below command while replacing “timeInSeconds” with the actual number of seconds.
shutdown -s -t timeInSeconds - Close the terminal window.
- With that, you scheduled a shutdown in Windows.
Steps with more details:
To set a Windows shutdown timer, search for PowerShell or Command Prompt and open it. I’m using PowerShell, but you can use Command Prompt too. In Windows 10 and 11, you can use the Windows Terminal.
In the PowerShell or Command Prompt window, execute the below auto shutdown command. Replace “timeInSeconds” with the number of seconds.
shutdown -s -t timeInSecondsFor example, if you want to auto shutdown Windows after 60 minutes, then the command will be shutdown -s -t 3600.

As soon as you execute the command, Windows will schedule a shutdown and displays a notification of the same.
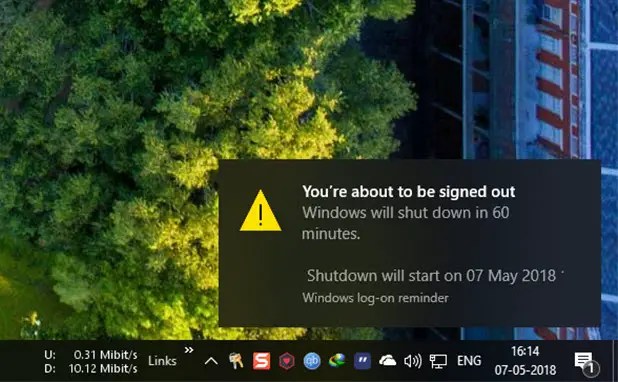
Once the timer runs out, it will display a warning asking you to save your work as the system is shutting down in a few seconds. There will be no cancelation option to abort the shutdown.
Scheduled Shutdown with Task Scheduler
If you want Windows to automatically shut down at a specific time every day or regular intervals, then you can schedule a shutdown using Task Scheduler. Here is how to do it in simple steps.
- Press the “Start” key.
- Search and open “Task Scheduler.”
- Click “Create basic task.”
- Type a name in the “Name” field.
- Press “Next.”
- Choose a “Trigger.”
- Press “Next.”
- Configure the trigger.
- Press “Next.”
- Type “shutdown.exe” in the “Program/script” field.
- Type “/s” in the “Add arguments” field.
- Press “Next.”
- Press “Finish.”
- Close the Task Scheduler.
- With that, you scheduled a shutdown with the task scheduler.
Steps with more details:
Search for “Task Scheduler” in the start menu and open it.

Click the “Create basic task” option in the Task Scheduler main window.

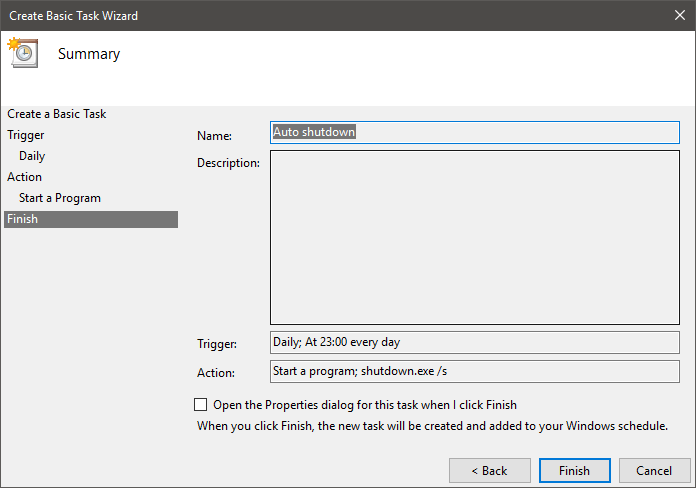
In the task creation wizard, enter a meaningful name & description, and click “Next.”

Now select how often you want to repeat the task. In my case, I want to shut down my system daily. So, I chose the Daily option. You can select whatever option you want.

Enter the time and click “Next.” Since I want to shut down the system at 11 PM, I’ve entered the appropriate time.
Note: If you use a 12-hour clock, don’t forget to select AM or PM. If you use a 24-hour clock, enter the time in 24-hour format, as shown in the image below.

Here, enter shutdown.exe in the “Program/Script” field and /s in the “Add Arguments” field. Click “Next” to continue.

Click “Finish” to complete the procedure.
Once the task has been created, you will see it ready to be executed in the Task Scheduler. The task will be executed, and the system will shut down on schedule according to your settings.

If you want to test the scheduled task, save all your work, right-click on the task and choose “Run.”
That’s it. It is that simple to make Windows scheduled shutdown.
Read more: How to rename scheduled tasks in Task Scheduler on Windows
In the future, if you no longer want Windows to auto shutdown, right-click on the task and select “Disable.” This action will disable the task. If need be, you can even delete the task by selecting the “Delete” option.

Oh, in case you are wondering, you can also cancel the scheduled shutdown on Windows. Follow the linked Windows guide to learn how.
I hope this simple and easy Windows how-to guide helped you.
If you are stuck or need some help, send an email, and I will try to help as much as possible.
The computer I have at home is programmed to shut down at a specific hour every day. There’s no shutdown action in the task schedule. Where else can I look at next?
Thank you!
If you can’t find any relevant task for auto shutdown in the task scheduler, maybe some program is do it via some other method. Monitor which programs are running at the time of the shutdown and try disabling them.
Scheduled shutdown can be canceled with the following command : shutdown -a
Thank you for the thread. My brand new laptop also shuts down at specific time every night. I can’t figure out how this could happen. Neither suggestion worked for me unfortunately. I cannot find the task in the task scheduler and I tried the “shutdown -a command but that doesn’t seem to work either. I contacted HP and Windows Help and they both recommended re-installing windows. I really do not want to do this. Do you happen to have any other suggestions? Thanks!!!!
Hi, Jeff.
Windows by default won’t shut down your computer. Maybe some software installed by you or the laptop manufacturer is shutting down the system every night.
That being said, it is highly possible that the system is going to sleep rather than shutting down. This is done to preserve the power/battery consumption. By default, Windows puts the system to sleep if it is unused for 30 minutes. You can change that by opening the Settings app (Win Key + I) and going to the “System → Power & Sleep” page.
Hi Bashkarla,
Thanks for your message. No my laptop is definitely “Shutting Down” at the same time every night. I read that you can go into task scheduler and manually schedule automatic shutdowns at specific times of the day (https://windowsloop.com/schedule-shutdown-windows/).
I also read (above and elsewhere) that you can override/cancel this with a “shutdown -a” command. I did this. But now my laptop shuts down at 8:30pm everyday (if its on at that time) instead of 9:30 pm like it was doing before. And I recently discovered that if the laptop was in sleep mode at that time, the next time I turn on my laptop, it opens windows for a split second and then it immediately shuts down again.
So frustrating. This is a brand new laptop. I don’t know what to do.
That is quite odd. In general, Windows doesn’t shut down the system automatically. There might some application that is shutting down the system. If possible, take a look at all the applications installed in your system and uninstall the one you don’t really need.
If that doesn’t work, try resetting the PC (Settings → Update & Security → Recovery) or reinstalling Windows.
very helpfull thanks